
Sigmoid function là một hàm rất nổi tiếng trong machine learning, nó như là một function hợp lý hóa đầu ra của model để các giá trị của output chỉ nằm trong (0, 1). Đây là dạng của hàm sigmoid :

Ta cũng thấy hàm này được dùng rất nhiều trong Neural Networks (NNs), giá sử ta có một mô hình như sau :


Công thức của dJ / dTheta(l)(i, j) = delta (l + 1) i * a (l) j
Do các giá trị của Theta tương đương nhau sau khi khởi tạo (kernel Gaussion) nên ta xét delta và a để xem nếu dùng sigmoid thì các delta có "cân bằng" nhau không.



Như ta thấy, giả sử hàm g(z) là sigmoid của biến z, vậy lim g -> 1 khi z -> +∞ ; lim g -> 0 khi z -> -∞
Mặt khác g(0) = 0.5, đây là một ngưỡng (threshold) rất hợp lý khi ta làm bài toán phân lớp (classifier). Cụ thể là nếu g(z) >= 0.5 thì ouput h là positive class, ngược lại sẽ là negative class. Hơn nữa, hàm sigmoid có tính đồng biến và g(0) = 0.5 vậy ta chỉ cần so sánh z = Theta' * X ( chính là weight nhân với input) với 0: Nếu z >=0, ta được positive class, ngược lại ta được negative class. Vậy đường thẳng Theta' * X sẽ là một đường phân định 2 class positive (1) và negative (0), nó còn gọi là decision boundary.
Ta cũng thấy hàm này được dùng rất nhiều trong Neural Networks (NNs), giá sử ta có một mô hình như sau :

Model trên có 3 layer : input layer có 3 neurons, hidden layer có 4 neurons, ouput layer có 2 neurons . Giả sử input "nối với" hidden qua bộ weight W1, hidden với ouput qua bộ W2, hàm activation dĩ nhiên vẫn là sigmoid.
Chúng ta đã biến thuật toán backpropagation, chú ý rằng, các đạo hàm riêng của J theo các Theta đều liên quan đến đạo hàm của hàm sigmoid :
Chúng ta đã biến thuật toán backpropagation, chú ý rằng, các đạo hàm riêng của J theo các Theta đều liên quan đến đạo hàm của hàm sigmoid :
Công thức của dJ / dTheta(l)(i, j) = delta (l + 1) i * a (l) j
Do các giá trị của Theta tương đương nhau sau khi khởi tạo (kernel Gaussion) nên ta xét delta và a để xem nếu dùng sigmoid thì các delta có "cân bằng" nhau không.
Ta xét đố thị của hàm số là đạo hàm của hàm sigmoid :
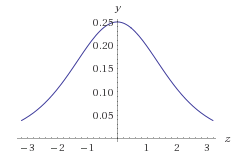

Ta thấy khi z dẫn đến vô cực thì giá trị sẽ dẫn đến 0, z nằm ở lân cận 0 thì giá trị > 0. Vậy với model ở trên ta thấy đạo hàm riêng của cost function với W1 khác nhiều so với đạo hàm riêng của cost function J với W2, cụ thể là với W1 và W2 được random theo kernel của Gaussion thì do z1 khác z2 khác nhau nên g'(a1) khác g'(a2), a1 chính là input X còn a2 là giá trị của các neurons ở hidden layer dễ thấy a2 nằm trong khoảng (0, 1) còn a1 thì không như vậy g'(a1) > g'(a2). (Nhưng thấy nếu input X đầu vào có các giá trị 0, 1 thì lại hợp lý). Vấn đề trên gọi là các đạo hàm riêng của cost function theo các weight "không cân bằng" nhau. Như vậy khi chạy gradient với tham số learning rate :
+ Với learning rate lớn, điều này có thể phù hợp với đạo hàm riêng của J với W2 vì nó nhỏ nên lượng giảm của biển vì thể sẽ không lớn, nên chạy gradient có thể gặp global minimum một cách nhanh chóng, nhưng đối với đạo hàm riêng của J với W1, vì nó rất lớn nhân với learning rate lớn nên độ giảm của Theta lớn, vì vậy có thể không gặp global minimum hoặc chạy rất lâu mới gặp

+ Với learning rate nhỏ, phù hợp với W1 vì đạo hàm riêng của J với W1 lớn nhân với learning rate nhỏ ta được độ giảm cho weight hợp lý nên khả năng cao là gặp global minimum, ngược lại vì đạo hàm riêng của J với W2 nhỏ nên độ giảm của weight quá nhỏ, nên khi chạy gradient rất lâu

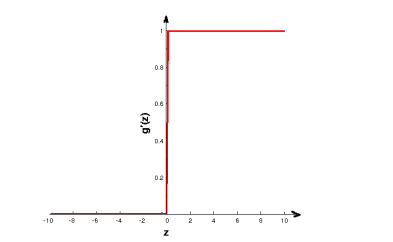
Như vậy ta cần một hàm có đạo hàm "cân bằng" nhau hơn để khi chạy gradient descent một cách hợp lý. Đó là hàm ReLU (rectified linear unit)

Đồ thị đạo hàm của nó :

Cảm ơn vì bài viết rất hay và dễ hiểu.
Trả lờiXóa